読み上げ白上シリーズのさらに続き。
実際に歌声の変換の方をやってみました。
今回はこれを作った話を書いていきます。
ボーカルの音源なんてありません
so-vits-svcを使うにあたって元となる音源が必要ですが、世の中にoff vocalの音源はあれど逆のボーカルのみの音源なんて都合よく公開されていない方が普通です。
というわけで、こういう動画を作ろうと思ったらまずボーカル音源をなんとかして用意する必要があります。これが第一の壁。
原曲の音源とoff vocalの音源があれば、理論上「逆位相で足してあげればボーカル取り出せるんじゃね?」と思うんですが、ボーカルって単一のパートだけじゃなくてハモリのパートが下にあったりとかするので、これだと実は上手くできない。(エフェクトとかも乗った状態の声が抽出できるだけなので実際役に立つか不明)
Demucsとか使っても結局同じことになるので、他の方法が必要です。
そうだ、耳コピしよう
「既存の音源からボーカルを取り出したりするのが面倒くさい」ということなので、今回は1からボーカルを合成するという手段を取りました。
どこで知ったのかは忘れましたが最近都合よくこういうのがあるというのを知っていたので、「じゃあNEUTRINOを使ってみるか」と。
最近の高品質な歌声合成ソフトといえばSynthesizer Vの方が有名かな?と思いますが、こちらは無料で使えるというのだから有り難い限りです*1。グラボ持っててよかった~。
NEUTRINOを使うのはガチの初めてだったので、以下のサイトなどを参考にしました。
NEUTRINOはあくまで入力された歌メロのデータから実際に音声を合成してくれるのみで、合成に使うデータをさらに別のソフトなどで作成する必要があります。
今回は上のサイトの通り、Domino(音程の打ち込み)とMuseScore(歌詞振り)を使うスタイルでやりました。これがまあそこそこ大変でした……。なんせ耳コピなんぞしたことなかったものですから……。
耳コピをするときの補助として大いに助けられたソフトが、WaveToneです。てか、補助というより必須。
習慣的に作曲をしていて、音感が十分にある人ならこういうソフトも要らないと思うのですが、一般人がやるなら本当に不可欠だと思います。
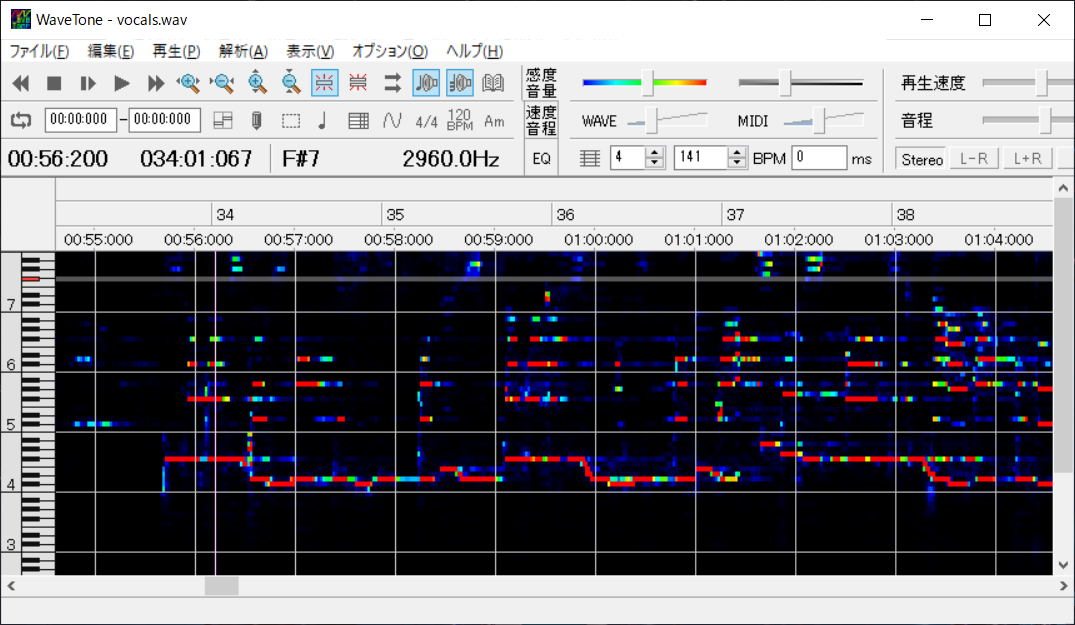
こんな感じでWaveToneで解析したスペクトログラムを横に置きながら、Dominoで歌メロの打ち込みをしていきます。

耳コピ初心者すぎて、本当に最初は音楽の「調」の勉強とかしました……。途中、WaveToneでなぜかうまく音を拾ってくれないゾーンがあったりするので、そういう部分は勘を頼りに音を置いたり消したりしていたのですが、本当にこれがめちゃくちゃ。一つ前の音より次の音が高いか低いかすら分からないんですよね。マジで自分の音感が破滅していることがわかりました。これって鍛えられるんでしょうか…。
普通に耳コピパートの作業に数日かけました。
打ち込みが終わったら、MIDIの書き出しをして今度はMuseScore上で作業します。
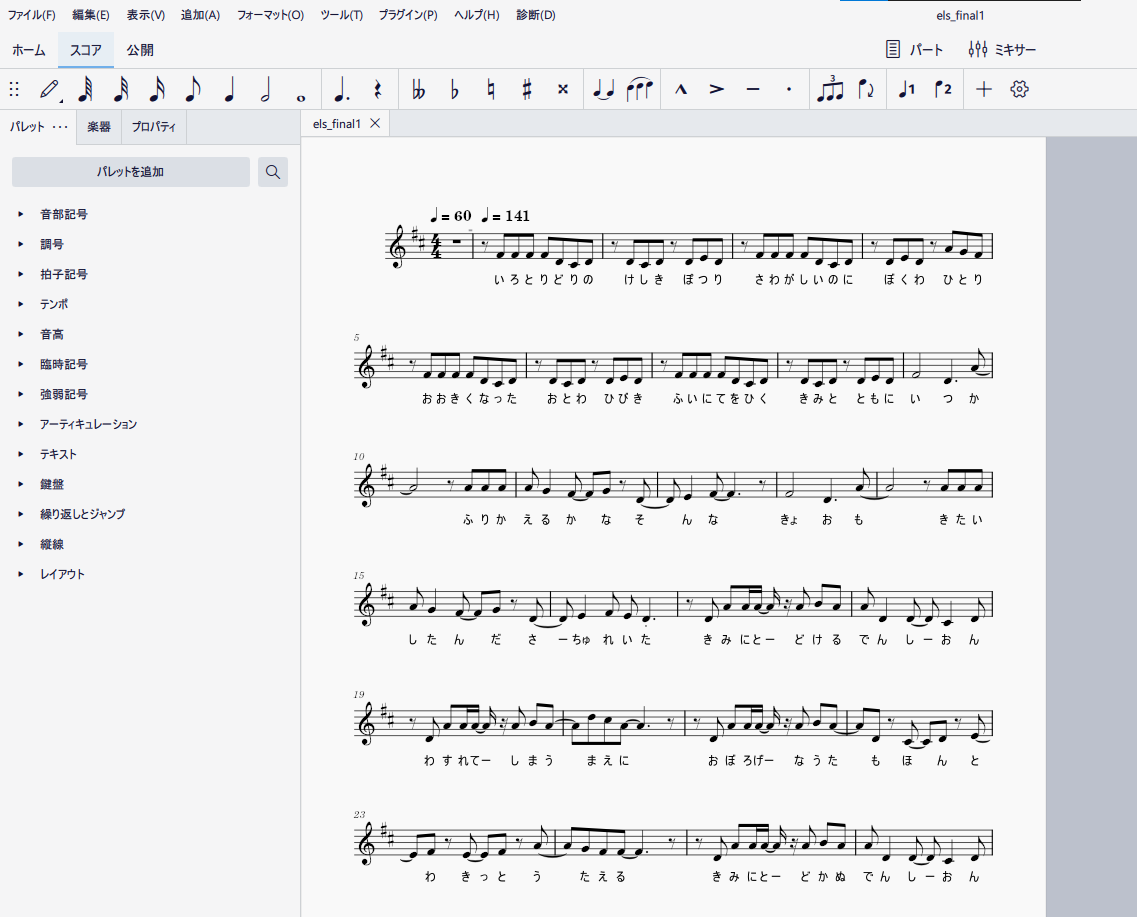
このパートは本当に歌詞を振るだけなので作業。助詞の「は」を「わ」にするとかを忘れずに。
これでMusicXMLの完成です。
歌声を合成してみる
ここまで来たら、NEUTRINOで歌声が合成できます。
so-vits-svcで音声変換をしても元の声の癖はそのまま残ってしまうので、変換したい人と似てそうな歌声ライブラリを選択すると良いと思います。
今回は最初「めろう」さんのまま使おうとしたんですが、実際に合成→変換してみたところなんか違うなあという感じだったので「No. 7」さんにしています。もしかしたらもっと似ている人がいるかも。要検証。
ピッチとかフォルマントの設定値は特に弄りませんでした。よく分からなかったので。
NEUTRINOはWORLDとNSFという2つの手法で音声を合成してくれますが、今回はNSFの方を採用しています。(質が良いらしい)
ボーカルの音源の長さは今回1分くらいだったと思いますが、合成は10秒くらいでできるのですごいですね。
ボーカルのミックスって、なんですか
普通にここが一番悩みました。まさかのボーカルのミックスとかいう作業を自分がやることになってしまい……。
当初はAudacityで適当に混ぜたらよくね?と思っていたのですが、Audacityの操作がよく分からなくて(←?)、手元にあるDAWのCakewalkを最終的に使いました。こちらもフリー。

「Cakewalk ボーカル ミックス」などで検索して出てきた記事などが大いに参考になりました。本当にありがとうございます。
ボーカル音源をエレクトロサチュレイタのあの感じにするにはどうしたらいいのかと、とりあえずリバーブだけつけたりしてみたんですが。リバーブ1つとっても設定値たくさんあるし、より近づけるにはどうしたらよかったのか、考えるべき点はたくさんです……。
でもまあ、素人感は満載にしてもそれらしくはできたかなと……。作曲なんてしていないのにこんなところでDAWを触ることになるとは思っていませんでした。不思議なこともありますね。
so-vits-svcについて
音声変換をするときにいくつか学んだことがあるのでメモです。
まず、推論時に-aオプションを付けることで自動でピッチの推定をしてくれるみたいな機能がso-vits-svcにはありますが、自分の環境では逆にこれを付けると音程が壊れました。よく分かりません。何もオプション追加しなくても普通にピッチを狂わせること無く変換できました。
あと、学習する時間の長さについて。
前回の記事を書いたとき(と、動画を作ったとき)は230epochくらい訓練したモデルを使用していましたが、今回は追加で学習をして777epochまで訓練を回しました。
なんか「so-vits-svc」で検索かけて出てくる情報を見るとみんな当たり前のように1000epoch以上訓練を回しているのですが、そんなに必要なんですかね……?
今ちょっと検索したら10k epochとかのやつもあってビックリしています。そういうもんなんでしょうか。
個人的には、今回使用したモデルで既に品質かなり良いのではと思っているのですが。(これ以上を目指すのはデータセットを綺麗にする必要がありそうだと考えています)
これからの話
今訓練したモデルでリアルタイムでボイチェンして遊べないかなあと格闘してます。
VC Clientを使ってみたのですが、なぜか出力がノイズにしかならず……。なんででしょう。
動いたら嬉しいな~。
*1:一部有償で別に販売されている歌声ライブラリもあります。