※記事タイトルに2023.01版 とある通り、一部情報が古かったりします。ご注意ください。
2022年の半ばごろから画像生成モデルが流行りに流行っていますが、その影響で一ヶ月前くらいの情報もこの界隈では「古い」情報となっていっています。
特にAUTOMATIC1111氏を中心に数多くのcontributorsにより開発されているStable Diffusion web UI *1 での知見をここにまとめてみます。
画像生成にこれから触れてみたい人向けっぽく書いてみますが、既に画像生成に慣れ親しんでいる人にも役に立つ情報もいくつかあると思います。
txt2imgについて
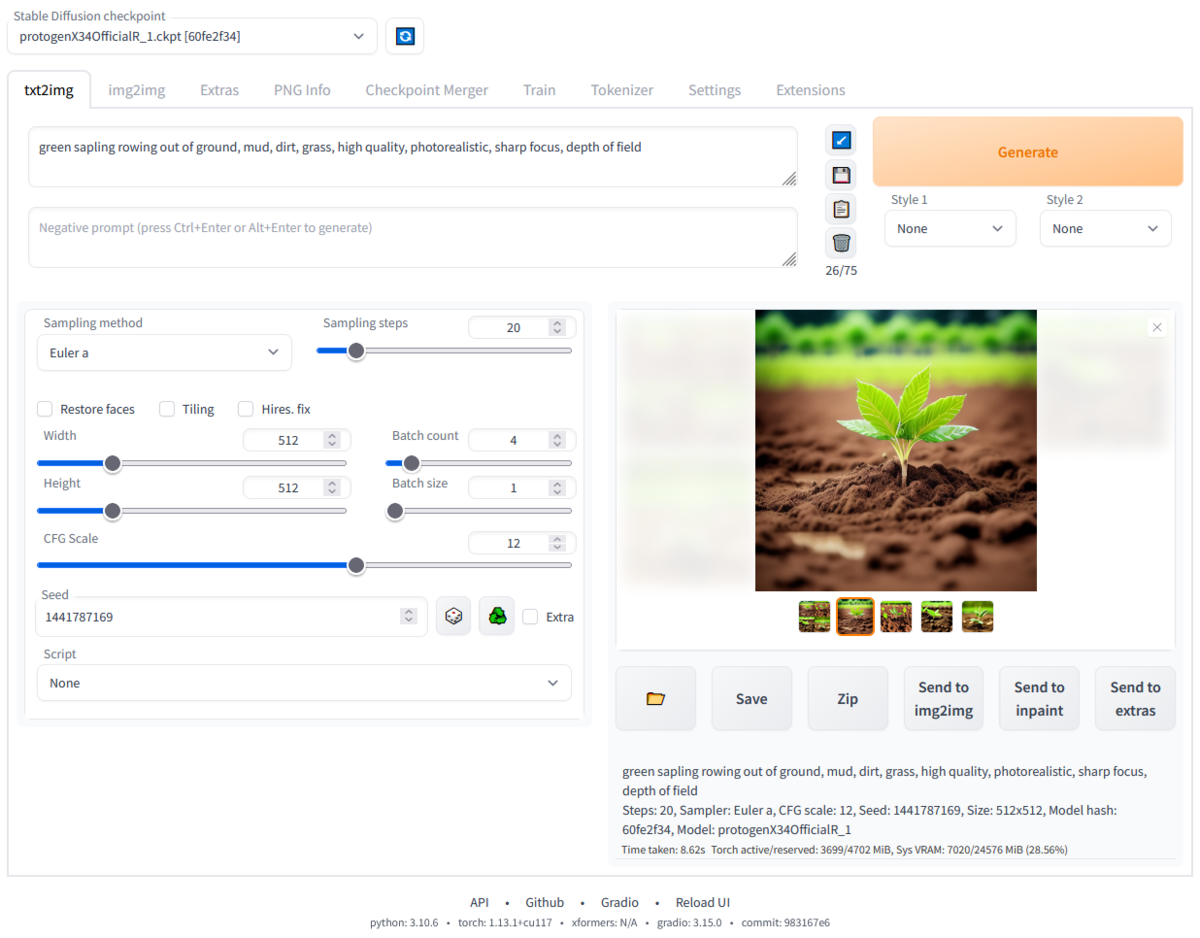
txt2imgタブ(公式リポジトリ より引用)
画像生成といっても実写系 とイラスト系 のざっくり二種類あると思いますが、自分の興味はイラストの方なので以降はこっちを念頭にして話します。
どのモデルを使えばいいか
画像生成を始めるには、まずは使うモデルを選ぶところからです。
3ヶ月ほど前はイラストと言えばNovelAI Diffusion一強時代でしたが、今は様々なイラストに特化したモデルが存在しています。
最近よく名前を聞くものだと、だいたいこの辺りでしょうか?モデルが公開されていないものだと、HolaraやNijijourneyとかもありますね。
とまあ、これだけ色々なモデルがあるので本当に好きに選んでいいです。それぞれのモデルが公開されているリポジトリ に行くとサンプル画像などがあるので分かると思いますが、どれも品質は高く元祖イラスト生成のNovelAIに劣らずといった状況です。
モデルの探し方ですが、最近のモデルはほとんどHugging Face かCivitai で公開されているものがほとんどだと思います。
huggingface.co
civitai.com
本当に様々なモデルがあるので、ここから新しいモデルを探してみるのも一興でしょう。機械学習 全般を取り扱っているサービスですが、Civitaiは画像生成に特化したサービスなので使いやすいです。
また、現在は更新されていないみたいですが、以下のようなモデル一覧ページがあったりしました。こういうのが今でもあるといいんですけどね。
rentry.co
VAEについて
少し専門的な話になりますが、Stable DiffusionのモデルはざっくりText Encoder、VAE、U-Netという3要素から構成されており、web UIではこのうちのVAEを簡単に交換して画像生成をすることができます。技術的な話をもっと知りたい方は、以下のような記事を参照するとよいと思います。
qiita.com
NovelAI以来、イラスト向けのモデルを使う際はイラスト用のVAEを使うことが一般的になっています。イラスト向けに訓練されたVAEはいくつか存在するのですが、通常使われているのは以下の3択のうちどれかでしょう。
3つ目のVAEはStable Diffusion用のもので特にイラスト用というわけではないのですが、イラスト用途にも普通に使うことができます。
VAEを変えると何が変わるの?という話ですが、比較してみます。
VAEの比較
3つの中だと、animevaeが柔らかい色になり自然なイラストっぽい印象を受けます。後者2つの違いは、パッと見あんま分からないですね。気になったら自分でも実験してみてください。
ちなみに、VAEをNoneに設定したまま生成してしまうと以下のような色あせたっぽい出力が得られます。
VAEの設定に失敗しているときの出力
このような出力になってしまっているときはVAEの設定をどこかで間違えてしまっていると思うので、設定を確認してみてください。(過去にweb UIのバグでVAEが上手く設定されない時期がありましたが、今は直っていると思います)
モデルのマージについて
先程色々なイラスト向けのモデルを紹介しましたが、最近はモデルをそのまま使うだけでなく、マージ(ブレンド )して使うということも多くなっています。
モデル同士をブレンド してあげることで、平たく言えば両者のいいとこ取りのような新しいモデルを自分で作成することができます。
note.com
こちらの記事はだいぶ古いものですが、現在のモデルにおいても同様のことができます。
また応用的な話になりますが、単純なマージだけでなく最近ではU-Netのブロックごとに異なる比率でモデルをマージするという手法も提案されています。
note.com
この技術は先程紹介したOrangeMixのうちAbyssOrangeMix2に実用されていたりします。
モデルのサイズがデカすぎるんだけど?
注意: 非推奨 です。代わりに以下の拡張機能 などを利用してください。
github.com
画像生成モデルのチェックポイントは平均5GBくらいあるので、いくつかモデルを使うくらいならいいのですが色々なモデルを試そうとするとストレージをかなり大きく占有してしまいます。
単純な解決策として、モデルを公開している人がファイル名の末尾に-halfとか-fp16がついたモデルを同時に公開してくれている場合、これを使うというのがあります。
精度を落として大丈夫なの?と思うかもしれませんが、実はこれほとんど影響がありません。もちろんオリジナル(単精度)のモデルと全く同じ出力が得られるわけではありませんが、気にならない程度のはずです (要検証) *3 。気になる方は、2種類のモデルをダウンロードしてみて比較してみてもよいでしょう。
追記:
しかしながら、複数バージョンのモデルが公開されていないことも多々あると思います。でも、そういう場合でも大丈夫です。モデルのサイズカット、実は自分ですることができます。
github.com
こちらのスクリプト を利用することで自分で半精度版のモデルを作成することが可能です。
ですが本題はここからで、実はもっとモデルのサイズを削減できます 。
先程Stable DiffusionはText Encoder、VAE、U-Netの3要素からできているという話をちらっとしましたが、このうちU-Net以外の部分を削ぎ落としてしまっても実はweb UI上で問題なく画像生成ができます。
以上の最適化をまとめて行うには、以下のようなオプションでスクリプト を実行すればよいです。
$ python prune.py -pca [サイズ削減したいモデルのパス] [出力先のパス]
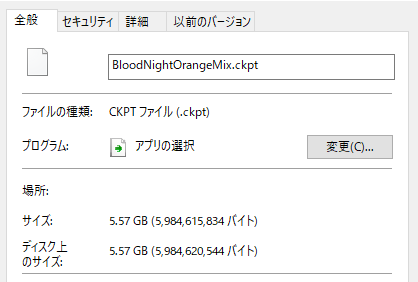
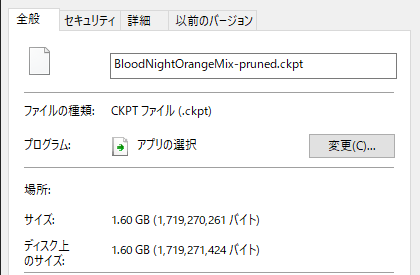
実際にこのスクリプト でBloodNightOrangeMix のチェックポイントを圧縮してみたところ、以下のような結果になりました。
ダウンロードしたチェックポイント
最適化したチェックポイント
容量が29%ほどに。こんな感じでかなりのストレージの節約が可能です。
このスクリプト 、safetensorsに対応してないので対応させようとしてforkしたはいいもののまだ何も手をつけてません。 時間が空いたときにやりたいですね(願望)。
2023/01/14追記:
safetensorsに対応させました。
github.com
プロンプトの書き方
Stable Diffusionでの効果的なプロンプトの書き方は、モデルが一般公開されて以来ずっと研究が続いている分野となっています。
写実系のモデルだと自然言語 風にプロンプトを書いたりしますが、アニメ調のモデルの場合大抵Danbooru のタグを利用して学習がされていることが多く、Danbooru のタグをたくさん知っていると得です。
danbooru.donmai.us
例えば特定のキャラク ターを生成してみたい場合、そのキャラク ターの投稿に付けられているDanbooru タグを参考にプロンプトを書くとよりそれっぽい再現ができます。
以下、プロンプト作成の参考になるものなどを紹介します。
まず、生成モデルにより生成された画像専門の投稿サイトである、AIBooru やMajinAI などを参考にするのがおすすめです。Danbooru よろしく、AIBooruもNSFW系の画像が特にフィルタされていないので閲覧する際はご注意ください。
aibooru.online
majinai.art
どちらもサービスも投稿された画像のメタデータ を閲覧することができ、どのモデルが使われているか、どんなプロンプトが用いられているかなどを知ることができます。
また、今となってはプロンプトの書き方などが若干古臭くはありますが、元素法典も良い教科書だと思います。
note.com
docs.qq.com
docs.qq.com
docs.qq.com
あと、以下は体のパーツごとなどに分けられたプロンプトのデータベースです。非常に有用。
lunarmimi.net
p1atdev.notion.site
プロンプトはより短いほうが好ましい?
特にNegativeの方のプロンプトについての話です。
元素法典が出た頃などは生成される画像の品質向上のため、長大なNegative promptが用いられていました。こういうやつです。
multiple breasts, (mutated hands and fingers:1.5), (long body:1.3), (mutation, poorly drawn:1.2) , black-white, bad anatomy, liquid body, liquid tongue, disfigured, malformed, mutated, anatomical nonsense, text, font, ui, error, malformed hands, long neck, blurred, lowres, bad proportions, bad shadow, uncoordinated body, unnatural body, fused breasts, bad breasts, huge breasts, poorly drawn breasts, extra breasts, liquid breasts, heavy breasts, missing breasts, huge haunch, huge thighs, huge calf, bad hands, fused hand, missing hand, disappearing arms, disappearing thigh, disappearing calf, disappearing legs, fused ears, bad ears, poorly drawn ears, extra ears, liquid ears, heavy ears, missing ears, fused animal ears, bad animal ears, poorly drawn animal ears, extra animal ears, liquid animal ears, heavy animal ears, missing animal ears, missing fingers, missing limb, fused fingers, one hand with more than 5 fingers, one hand with less than 5 fingers, one hand with more than 5 digit, one hand with less than 5 digit, extra digit, fewer digits, fused digit, missing digit, bad digit, liquid digit, colorful tongue, black tongue, cropped, watermark, username, blurry, jpeg artifacts, signature, 3D, 3D game, 3D game scene, 3D character, malformed feet, extra feet, bad feet, poorly drawn feet, fused feet, missing feet, extra shoes, bad shoes, fused shoes, ...
まあ、長い。
ところが、現在ではこういうことはしないのが普通です。代わりに、以下のembeddingが用いられていることが多いと思います。
huggingface.co
embeddingってtextual inversionで使うやつじゃないの?と思うのですが、どうやら概念学習にも使えるようです。
こういうこと(7th Layerのリポジトリ から引用)
ざっくり言えば、bad_promptは上のような大量のNegative promptを数トーク ンにまとめてくれるみたいなものです。これが非常に便利なため、現在ではこれが主流のように思います。
これが要因かは分かりませんが、最近はNegative promptはシンプルに、みたいな流行りを感じます。
bad_promptと同様に、以下のnegative用のembeddingもおすすめです。
huggingface.co
プロンプトの「汚染」について
少しディープな別に知らなくても良い感じの話です。
画像生成で少し遊んでいると、色指定したはずの服や髪などが違う色になったり、そういう場面に出くわすことがあります。これは「色汚染」と言われたりする現象です。
まずStable Diffusionが画像生成をするとき、CLIPが与えられたプロンプトをトーク ンと呼ばれる単位に分割します。プロンプトを入力しているとき、入力欄の右下に出ているx/75みたいなやつが現在の使用トーク ン数になっています。
ここで、各トーク ンは先頭に近いほど生成される画像に対する影響力が強く、逆に末尾に近いほど相対的に影響力が弱くなります(Transformerの仕様らしい)。これが基本的な仕組みです。
ここからがweb UIに特有の話で、Stable Diffusionは通常75トーク ンまでの長さのプロンプトにしか対応していない(それを超えた部分は無視される)のですが、web UIではその上限がなく(225トーク ンまで?真偽不明)より詳細な指定をモデルに与えることができます。トーク ンごとに入力を区切ることで実現されているらしく(75トーク ンのまとまりを一般的に文節と呼ぶっぽいです) 、この影響で76トーク ン目は再び1トーク ン目と同じ影響力を持つようになります。
この仕様のため、長いプロンプトの真ん中あたりに単語を新しく挿入したりすると意図せずガラッと出力が変わってしまったりします。この文節の区切りを意識できるようになると上手い生成ができるようになるかも。
で、ここまで話すと「汚染」の話ができます。と思ったのですが、自分もまだ完全には理解できていないので偉大な先行研究を紹介するにとどめておこうと思います。
mag-caps.hatenablog.com
人間的に正しい形容詞 名詞を使うのではなく、名詞 形容詞 名詞とすると「色移り」が多少軽減できるらしいです。自分もこれから使ってみようかなと。
カンマはトーク ンを消費するので付けなくてもいいのではみたいな話もあるみたいです。深い。
プロンプトの入力補助ツール
NovelAIみたいにweb UI上でもDanbooru タグが補完できたらなあ、と思ったあなた。なんと、拡張機能 があります。
github.com
マジでプロンプトの入力の効率が上がる(+typo 軽減になる)ので、Danbooru タグを使うモデルを普段使っている場合は入れて損はないです。
Sampling methodについて
プロンプトが決まったら、次に決めるのはSampling methodでしょうか。
web UIで使えるサンプラー は最初は10個も無かったのですが、今ではアプデされて20個くらいになりました。さて、どれを使ったらいいものか。微分方程式 の数値解法なんて知らんし。
最初期はみんなEulerかEuler a (ancestral)を使ってた気がしますが、最近はDPM++ 2M Karrasを使ってる人が多い気がします。自分も普段これです。
あとはたまにDPM++ SDE KarrasとDDIMをみかけたりするかな、くらい。
全く適当に選んでいるわけではなくて、ここのサイトに書かれているようにサンプラー はそれぞれ特徴があります。
dskjal.com
自分はDPM++ 2MやPLMSを試したりしていた時期がありましたが最終的にDPM++ 2M Karrasに落ち着きました。
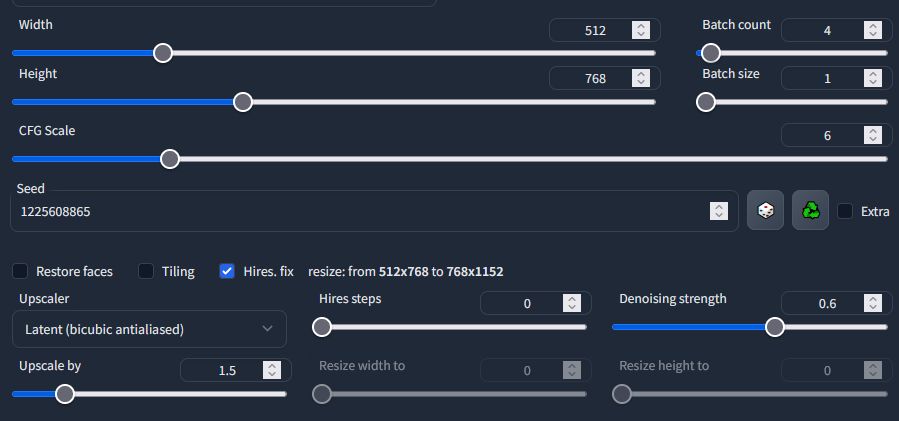
Hires. fixについて
正月くらいに仕様が変わったので書いておきます。
txt2imgタブ拡大図
Hires. fix は、高解像度の画像を生成したいときに使う機能です。高解像度にすると、イラストの書き込みが自然に増えてちょっと良い感じになります。
「いや、でかい画像生成したいなら最初からWidthとHeightをデカくすればいいじゃん」と思うのですが、これをすると人体などが破綻します……。
具体例みたいなのは、web UIのWiki のFeatures/Hires. fixの項を見ていただけると良いと思います。
github.com
これはおそらく学習した画像のサイズ(SDv1時代ならおそらく512x512)とかけ離れたサイズの出力はできないという特性なのだと思うのですが、これを間接的に解決してくれるのがHires. fixです。
(現行の)Hires. fixではまず通常のWidth/Heightで設定されたサイズで画像を生成し、これを指定されたUpscalerでUpscale byの値倍に拡大しさらにそれをimg2imgにかけます。このように直接大きな解像度の画像を生成するのを避けることで先程の問題を回避しています。(断定で話していますが100%の確証はないです、多分こんな処理のフローだと思います)
Hires. fixの際に使うUpscalerをLatent系にすると、さっき言ったように高解像度になった分だけイラストの細部が描かれるようになり嬉しいです。
で、Latentが名前についてるUpscalerいっぱいあるやんという感じなのですが、正直現時点では自分もどれがいいのかよく分かりません。そもそもLatentとしか書いてないやつはなんなん?って感じですし。
普通の画像補間アルゴリズム っぽく、まあnearestよりはbicubicの方が品質が良いんだろうなということで今の設定になっているのですが、そもそも潜在空間上で何を補間しているのかもよく分からん。解説がほしいですね。
Latent (nearest-exact)とLatent (bicubic antialiased)で計算コスト違うのかな、と思いましたが特に生成時のイテレーション の速度に影響があるようには見えませんでした。本当によく分かりません。
そんなわけで、現時点での私のおすすめUpscalerはLatent (bicubic antialiased)です。
Denoising strengthは初期値0.7ですが、高すぎる気がするので0.6くらいがいいような。0.5未満にすると出力がノイズっぽくなってしまうので、0.5-0.7くらいで調節すると良いと思います。
追記:
aioe.fanbox.cc
生成画像のファイル名をカスタムする
txt2imgで生成した画像はデフォルト設定のままだとoutputs/txt2img-imagesディレクト リ内に[連番id]-[seed].png という形式でどんどん保存されていきますが、これだと管理がめんどくさいです。web UIの設定をいくつか変更してあげることで、もう少し良い感じの管理ができます。
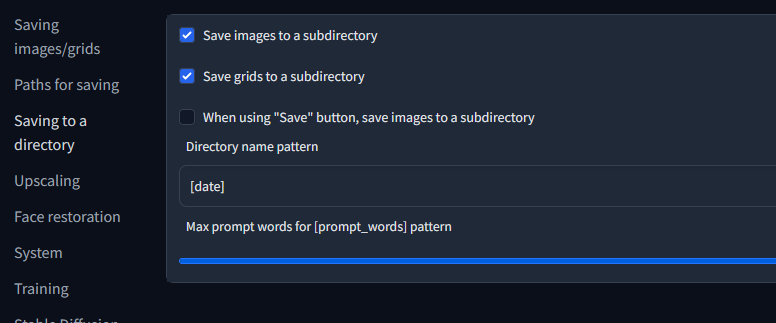
Settings/Saving to a directory
私の場合、まず日付ごとにサブディレクト リに分けたかったので、上のような設定にしました。Directory name patternの部分にマウスオーバーすると日付以外の使用可能なタグを見れます。複数組み合わせられるので、日付とモデルのハッシュ値 によってフォルダ分け、みたいなのも可能です。お好みでどうぞ。
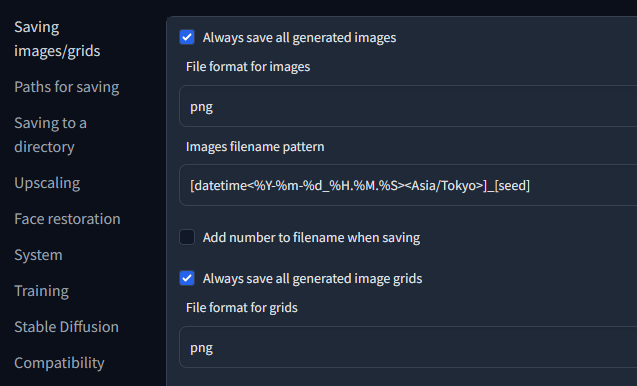
Saving images/grids
ファイル名の設定は一番上のタブでできます。
web UIはデフォルトだとファイル名の先頭に連番で番号を付けてくれますが、私は番号より日時にしてくれたほうが嬉しかったのでこの設定にしました。末尾のseedの部分を除くと、Minecraft のスクリーンショット と同じ命名規則 になっています。日時にしておくと、違う日に生成した画像を混ぜたときに順番になってくれて嬉しいです。
seedは「一応書いておくと便利かな」と思って残してありますが、正直要らないかも。
同一時刻(秒まで同じ)に複数の画像が生成される可能性がある場合には、datetimeのフォーマット指定の部分を%Y-%m-%d_%H.%M.%S_%fのようにしておくといいです。(同名のファイルは上書きされてしまうため)%fは現在時刻のマイクロ秒部分(6桁、leading zerosあり)です。
Additional Networks
便利な拡張機能 の紹介です。
github.com
追加学習した分のデータをどのモデルでも使えるようにしてくれる拡張機能 です。
生成した画像がたまに真っ黒になってしまうときは
(生成した画像が全て真っ黒になってしまうときは別の問題です)
コマンドライン 引数に--no-half-vaeを追加してweb UIを起動してあげると直ると思います。
別の節でも話した通りweb UIはデフォルトでモデルを半精度にして読み込んでいますが、VAEをfp16にしてしまうとバグってしまう(?)みたいです。
生成の高速化とVRAM消費削減
web UIはxFormers による推論の高速化に対応しており、とても便利です。
github.com
github.com
特にPascal 以降のGeForce のグラボ(GT/GTX 10xx以降)を利用している人なら自動でインストールができるので導入しておくべきだと思います。
また、xFromersが利用できる環境でない人向けの軽量化の手段はまだあって、例えばこちらのプルリクエス トで導入されたSub-quadratic Cross Attention layer optimization というのがあります。
github.com
こちらはコマンドライン 引数に--opt-sub-quad-attentionを追加することで利用できます。(まだ公式のWiki には記載されていないので知らない人も多そう?)
xFormersと同時に有効にすると、xFormersが優先されます。
一枚の絵に複数のキャラを描画するには
例えば2人のキャラク ターを描きたいと思ったとき、素のStable Diffusionではプロンプトがどちらのキャラク ターに対する指定なのか制御できないため、望み通りにキャラク ターを生成するのはかなり難しい作業です。
しかしながら、以下の拡張機能 を用いることで複数人のキャラク ターの生成がかなりの精度で実現できるようになります。
github.com
note.com
2人だけでなく、3人なども可能です。
img2imgについて
inpaintingについて書こうと思ってたんですが、いつか追記します。
別の記事にするかも。
リンク集
本文では紹介しなかったものなど。